上百个存储资源上云时碰到一个棘手问题,如何平滑地切写?
通常切写可以通过dba改dns(+强制read only)或 业务改配置,但会产生一些问题,如:连接异常断开、部分数据 旧主→新主 同步冲突/失败、数据丢失等异常,归根结底是这些方式不够平滑,dns在各机房生效有时差、业务各进程还可能会缓存dns解析结果、业务内部长连接无法优雅断开
引入中间件又会增加运维复杂度,多一层故障源。运维层面没有提供解决方案,那只能业务自己来想法办
所以实现了这个平滑切写模块,平滑切master的要点是:定时切配置,切换过程“卡”住几百ms。
步骤1:做级联同步,写老读新
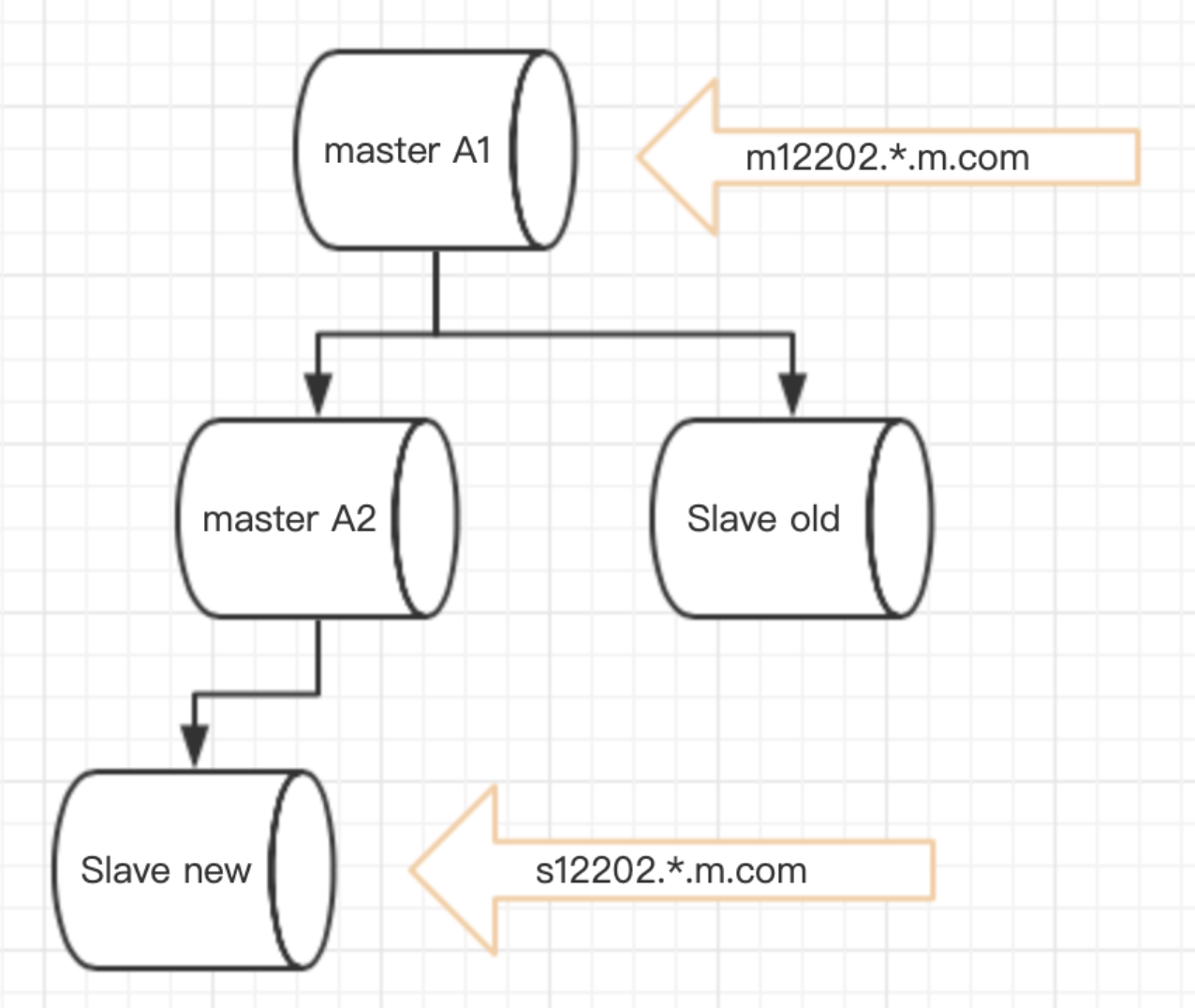
A1是老master,A2是新master,由域名指向得知,目前状态是写老master,读新slave
步骤2:配置定时切
将新配置混合老配置文件发布到生产环境,在配置里(也可以做成后台控制)设定好切写时间点
到时间点的时候所有写请求卡住几百ms,getPDO()方法里写好逻辑注销旧连接(A1),重新连接DB(得到A2)
新配置可以临时使用IP直连也可以启用新域名,只要让A2与A1的host不一样即可
步骤3:下线旧master和slave
切写完成,删除无用配置,规范master的host。安全下车
关于卡住几百ms的设定有2个好处:
1、最大限度兼顾机房机器间微小时差,卡顿期间留下write空窗期
2、给A1同步数据到A2留下足够的时间窗口
所以具体需要卡几百ms由最懂业务的你来决定,建议500ms左右,这样即对用户影响比较小,也能保证时间窗口足够
这套逻辑实践在上百个资源切写中完美平滑完成任务

近期评论